

To be held by GoToWebinar 17 February 2023, 15-17 CET (9 am New York, 11 pm Tokyo, 730pm New Delhi)
FEATURED
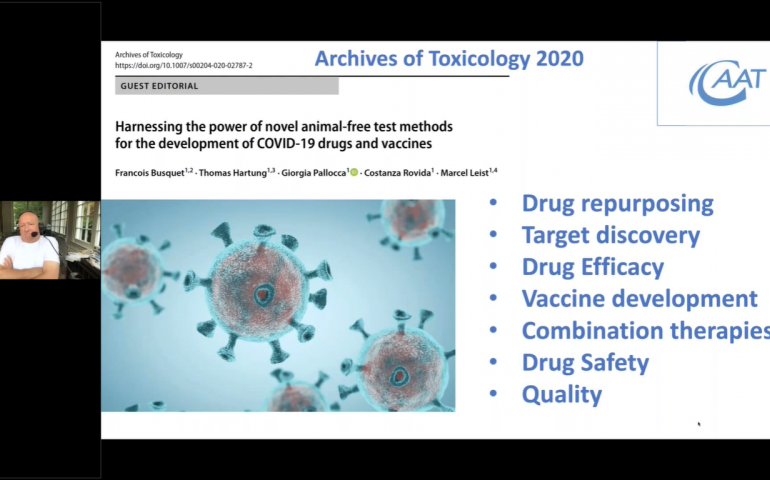
Harnessing the power of novel animal‑free test methods for the development of COVID‑19 drugs and vaccines
OpenTox webinar 6/11/2020
FEATURED
Utilizing blockchain technology to offer “trust as a service”
OpenTox webinar 01/09/2020
FEATURED
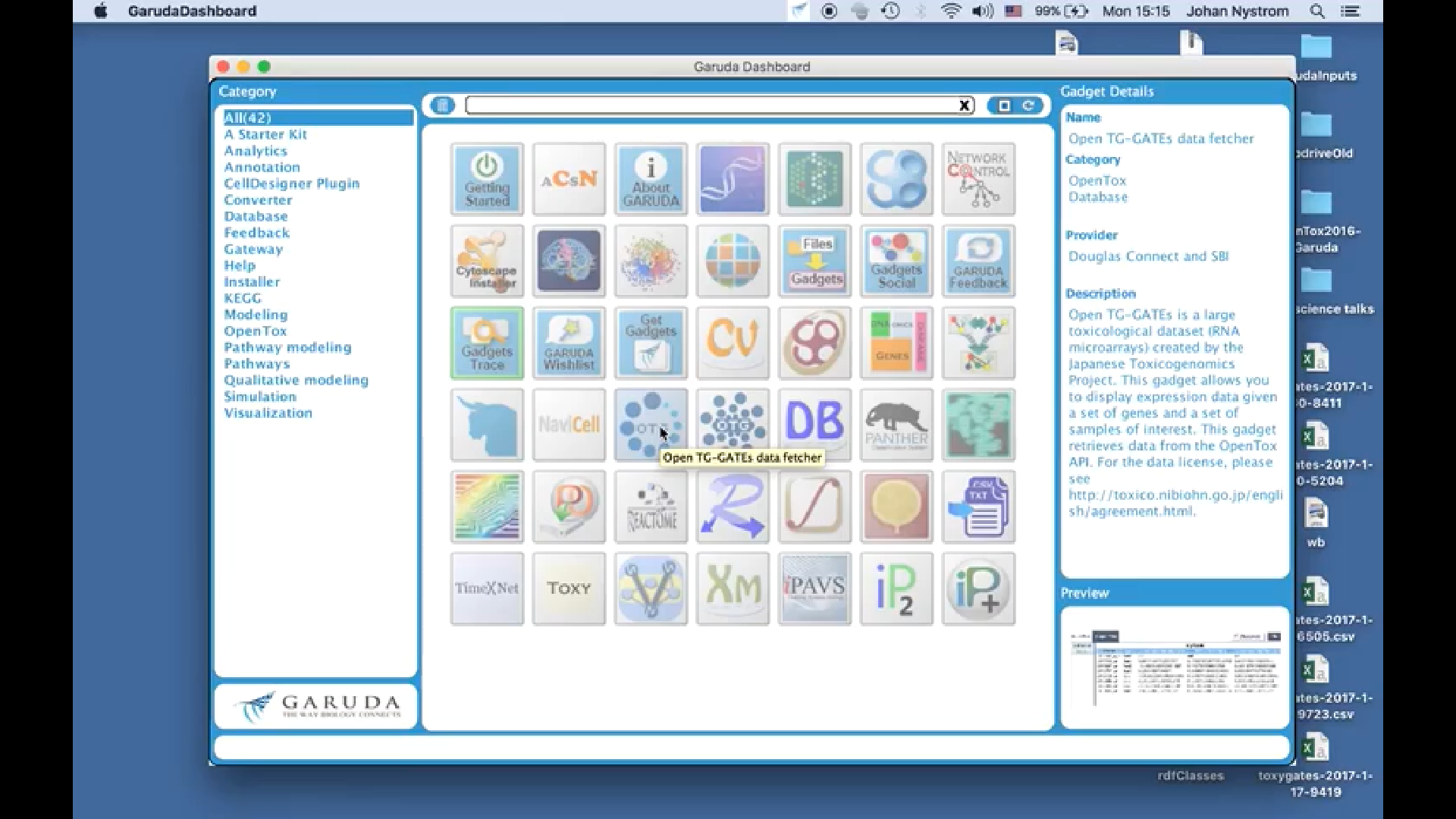
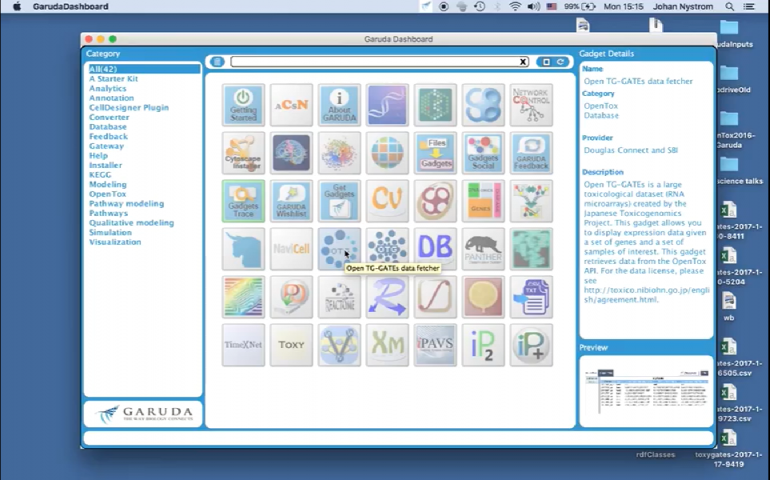
OpenTox Garuda Platform
OpenTox Garuda Gadgets
Garuda is a connectivity and automation platform for various tools and applications (called Gadgets)
The platform hosts an array of gadgets with diverse GUIs and functionalities on a connective platform
Garuda aims to be “the way biology connects”

Harnessing the power of novel animal‑free test methods for the development of COVID‑19 drugs and vaccines

Utilizing blockchain technology to offer “trust as a service”
OpenTox Garuda Platform


Type of position - Part Time

To be held by GoToWebinar 25 March 2021, 16-17.30 CET (i.e., starting at 11 am New York, 3 pm London, 4 pm Zurich, 8.30 pm New Delhi, 12 am Tokyo)

We invite members of the OpenTox community to submit an abstract for the OpenTox 2020 Challenge.

The first OpenTox India workshop and community meeting were held in Hyderabad 1-3 March 2019.

You should send your cover letter and CV/resume (including education, experience, job descriptions, references, availability etc.) Please also send 1-3 descriptions or examples of your work.
20September
Virtual Conference Room
The OpenTox 2021 Conference activity will take place online 20 - 24 September